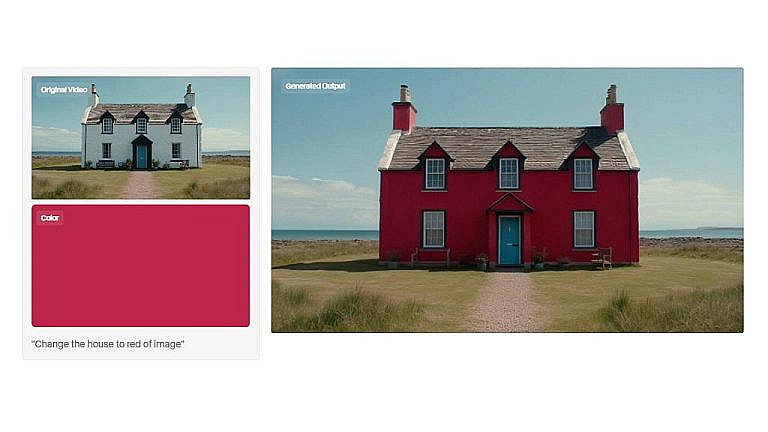
Генерация музыки с помощью Transformer-GAN
Исследователи из Южно-Китайского технологического университета представили новый алгоритм генерации музыки, основанный на трансформерах и генеративно-состязательных сетях (GAN). Модель под названием SCTG (Style-conditioned Transformer-GANs) способна создавать полноценные музыкальные композиции с нуля, учитывая заданный стиль — будь то эмоциональная окраска или манера конкретного композитора.
Традиционные rule-based модели опираются на музыкальную теорию, но не могут уловить глубинные структуры, что ограничивает разнообразие результатов. Глубокое обучение предлагает три основных подхода:
- GAN — сложны в обучении,
- VAE — плохо справляются с длинными последовательностями,
- Трансформеры — не всегда контролируют стиль.
Предыдущие попытки добавить стилевое управление игнорировали структурное восприятие модели. SCTG исправляет этот недостаток.
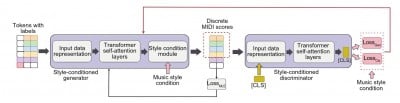
Архитектура модели
Ключевые компоненты:
- Представление данных: MID-последовательности с встроенной стилевой информацией.
- Стилевой линейный трансформер: встраивает стиль в скрытое пространство модели.
- Патч-дискриминатор: усиливает обучение за счет дискретных оценок.
Стиль влияет на всю выходную последовательность, а не только на отдельные элементы.
Результаты
Тесты на датасетах EMOPIA (эмоции) и Pianist8 (стиль композиторов) показали:
- Лучшие показатели в метриках стилевого расстояния (SD) и точности классификации (CA).
- Высокую согласованность стиля и близость к оригинальным данным.
- Субъективные оценки слушателей: максимум по ‘естественности’, ‘богатству’ и общему качеству.
Любопытно, что удаление любого из компонентов Loss₍Cls₎ или Loss₍Gan₎ сразу ухудшало результаты. Видимо, они действительно критичны для работы дискриминатора.
Модель уже сейчас выглядит готовой к практическому применению — например, в генерации саундтреков или инструментовке. Главное, чтобы музыканты не начали беспокоиться о конкуренции.