ИИ учится связывать зрение и звук без участия человека
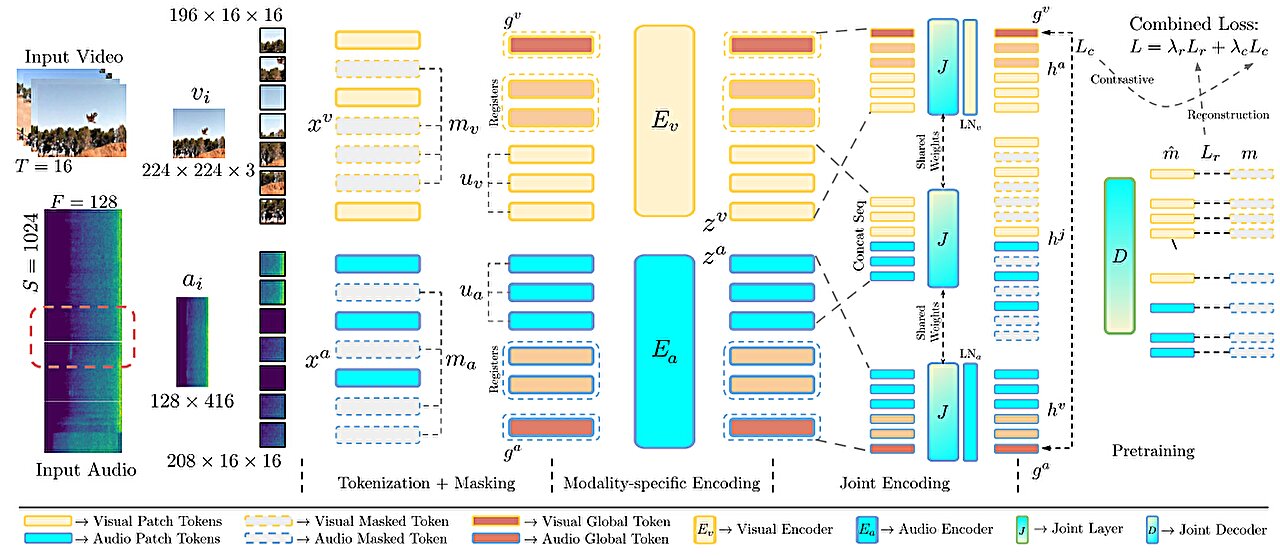
Исследователи из MIT и других учреждений разработали улучшенную версию модели CAV-MAE, которая учится связывать звук и изображение без участия человека. Новая модель, CAV-MAE Sync, разбивает аудио на более мелкие сегменты, что позволяет точнее сопоставлять звуковые события с конкретными кадрами видео.
Модель обрабатывает видео и аудио параллельно через отдельные энкодеры. Аудиоэнкодер работает с более мелкими временными интервалами, чтобы лучше согласовываться с визуальными кадрами. Оба модальности взаимодействуют через совместный слой и декодер, обучаясь как на восстановлении данных, так и на контрастном сравнении.
Ключевые улучшения:
- Разделение аудио на короткие окна для точного сопоставления с кадрами.
- Добавление глобальных токенов для контрастного обучения.
- Регистрационные токены, помогающие фокусироваться на важных деталях для восстановления.
Практическое применение
Модель может автоматически находить соответствия между звуком и изображением — например, сопоставлять хлопок двери с кадром её закрытия. Это полезно для:
- Автоматической разметки мультимедийного контента в журналистике и кинопроизводстве.
- Улучшения понимания роботами окружающей среды, где звук и изображение взаимосвязаны.
В тестах CAV-MAE Sync показала более высокую точность в поиске видео по аудиозапросу и классификации сцен по сравнению с предыдущими методами, включая более сложные модели, требующие больших объёмов данных для обучения.
Перспективы
Исследователи планируют:
- Интегрировать более совершенные модели генерации представлений данных.
- Добавить обработку текста для создания мультимодальных языковых моделей.
Работа будет представлена на конференции CVPR 2025 в июне.





